Analyse de marché – YouTube
Depuis plus de dix jours, je construis une méthode de collecte et d’analyse semi-automatisée pour étudier un échantillon de 26 chaînes YouTube dédiées au vélo — 2 par cluster (voir Folk #5).
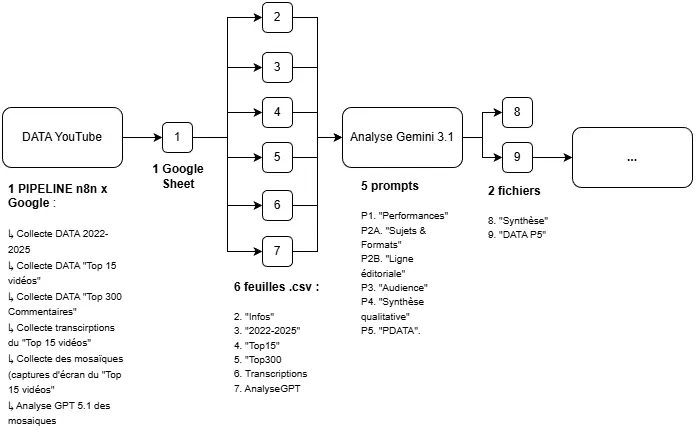
J’ai commencé par élaborer un pipeline qui collecte, pour chaque chaîne :
- les données de toutes les vidéos publiées entre 2022 et 2025
- les 15 vidéos les plus populaires
- les 300 commentaires les plus pertinents
- la transcription de chaque vidéo du top 15
- une analyse visuelle par IA à partir de captures d’écran
Pourquoi ces données précises ? Par intuition — je cherchais le bon équilibre entre quantité et qualité, avec les ressources à ma disposition, pour répondre à deux questions :
- Qui sont les acteurs du vélo sur YouTube FR — créateurs et communautés ?
- Quelle est la valeur créée par chaque chaîne ?
En écrivant cet article, je n’ai que des embryons de réponses. Je touche au but mais je n’ai pas encore effectué les analyses transversales finales.
Voici ce que j’ai réalisé pour l’instant :
Je suis à la bourre…
…Et c’est à cause de mes choix d’infrastructure et opérationnels :
- Mon serveur VPS (qui fait tourner n8n) a planté plusieurs fois — j’ai dû le brider pour éviter les crashs en cascade de mon pipeline.
- L’API YouTube et les outils de scraping via Apify ne collectent pas directement les vidéos les plus populaires d’une chaîne : j’ai dû tout récupérer depuis sa création, puis filtrer.
- Google impose des quotas de requêtes à la minute (comptes gratuits), ce qui freine la collecte massive.
- Claude et Gemini hallucinent sur des classeurs multi-feuilles — j’ai converti chaque feuille en CSV et « orienté » les IA pour fiabiliser les résultats.
- J’atteins souvent les quotas journaliers de mon forfait Pro Claude – j’ai basculé une partie du travail sur Gemini, mais fiabiliser les résultats avec l’IA de Google est… laborieux.
Aparté sur l’automatisation & l’IA
C’est la grande mode de l’automatisation et des « agents IA ». Deux contraintes opérationnelles sont pourtant peu évoquées :
- Automatiser demande des contrôles qualité rigoureux, à des étapes précises dans la chaîne. S’assurer que la donnée collectée en début se retrouve intacte en bout de chaîne n’est pas une mince affaire — surtout quand le volume est élevé. Une des clés : diviser le travail et éviter les workflows « usines à gaz ».
- Une IA produit toujours un rendu séduisant — bien présenté, structuré, chiffré, sourcé. C’est merveilleux… jusqu’au moment où vous croisez avec les fichiers sources. Le masque tombe : hallucinations, biais de confirmation, résultats qui varient d’une requête à l’autre. Et les auto-justifications des IA sur leurs propres dérives ne tiennent pas la route… Ce qui complexifie grandement la résolution de problèmes.
Pour autant, l’intégration de l’IA dans mon flux de travail est vitale. Elle me permet de limiter les ressources humaines et financières engagées, de mieux formuler mes questions, d’explorer des pistes insoupçonnées, et de déléguer ce que je maîtrise le moins.
Mais comme pour tout outil, l’intégration de l’IA n’a de valeur que si elle est fiable : avec les mêmes données et les mêmes instructions, elle doit produire des résultats quasi identiques. Je n’attends pas de créativité de sa part. J’attends surtout de la fiabilité et de la réactivité. Pour atteindre vos objectifs, vous devez élaborer la bonne méthode — mi-sur mesure, mi-reproductible/évolutive.
Voilà, pas de contenu « pur » Folk aujourd’hui.
En attendant dimanche,
Bonne semaine,
Matthieu
Ressources (Github)
→ Toutes les ressources sont disponibles ici (Github).
Pour ne rien rater de l’aventure Folk
→ Abonnez-vous à la newsletter de Folk :
Laisser un commentaire